

EXPERIMENTAL DESIGNS

SPECIFICATION: EXPERIMENTAL DESIGNS: REPEATED MEASURES, INDEPENDENT GROUPS, MATCHED PAIRS, QUAIS,
CONTROL: RANDOM ALLOCATION AND COUNTERBALANCING, RANDOMISATION
EXPERIMENTAL DESIGN DEFINITION:
Once a researcher has designed their study and decided to experiment, they must decide how to organise participants into different conditions. This is a crucial part of experimental research.
Unlike non-experimental studies, where all participants usually do the same thing, experiments involve different conditions or levels of the independent variable. For example, one group might receive a treatment, while another does not.
This raises important questions:
How should participants be allocated to each condition?
What options are available?
Are there advantages and disadvantages to different methods?
This is where experimental design comes in. It refers to the different ways researchers can structure the groups in their experiment to test the effect of the independent variable.
There are three main types of experimental design commonly used in psychology:
Independent groups / between-subjects design
Repeated measures design
Matched pairs design
In some cases, researchers may use a quasi-experimental design, such as a between-subjects quasi-experiment, where groups are preexisting rather than randomly assigned. Still, the test structure is similar to an independent group design.
QUASI EXPERIMENTAL DESIGN The word “Quasi” indicates similarity. A quasi-experimental design is similar to an experimental design but not the same.A quasi-experiment may also use a between-subjects design, which looks similar to an independent group design. Still, the key difference is that participants are not randomly allocated—they may already belong to natural groups (e.g., age, gender, or ability level). Although it uses exact comparisons, it is quasi-experimental, not entirely experimental.
Each type of design has its strengths and weaknesses, which will be explored in detail later.
MATCHED PAIR DESIGN
MATCHED PAIRS DESIGN
In a Matched Pairs Design, participants are matched in pairs based on key variables that are relevant to the study (e.g. age, IQ, gender). One person from each pair is randomly assigned to one condition, and the other to the second condition.
This design is like a hybrid between repeated measures (because it controls individual differences) and independent groups (because each participant still only does one condition).
For example:
A researcher might match participants based on their IQ scores, so each condition has equally smart participants. Then one person from the pair does the “with music” condition, the other does the “no music” condition.

WHEN TO USE MATCHED PAIRS DESIGN
When individual differences are likely to affect the outcome, but you don’t want participants to do both conditions (e.g., to avoid order effects),
When you can pre-test participants to find a matching variable (e.g. reading age, memory ability).
ADVANTAGES
Controls individual differences – Matching makes groups more equivalent (e.g., they have the same average IQ in both).
No order effects – Each participant only does one condition, so there’s no fatigue or practice effect.
Reduced demand characteristics – Participants are less likely to guess the aim, since they only take part once.
DISADVANTAGES
Matching is time-consuming – You must pre-test and carefully match participants before the study begins.
Perfect matching is impossible. Even when matched on one variable (e.g., age), participants might still differ in others (e.g., motivation and experience).
If one participant drops out, their pair’s data becomes unusable, reducing the sample size.
Matched pairs are ideal when you want to control individual differences without having participants repeat tasks, but they take more preparation than other designs.

INDEPENDENT GROUP DESIGN
In an Independent Group Design (also known as a Between-Subjects Design), each participant participates in only one condition of the experiment. Participants are randomly allocated to the independent variable (IV) levels.
For example:
One group might complete a task with music,
The other group completes the same task in silence.
This means that each participant only experiences one version of the IV, and different participants are used in each condition.

WHEN TO USE INDEPENDENT GROUPS DESIGN
Sometimes, an Independent Groups Design must be used. For example:
When testing sex differences, you can’t have the same participant in both the “male” and “female” conditions.
Participants cannot be in both groups when comparing age groups, such as under-30s vs. over-60s.
These situations require different participants per condition by definition.
ADVANTAGES
No order effects – Participants only do the task once, so there’s no risk of practice, fatigue, or boredom.
Less risk of demand characteristics – As participants only complete one condition, they are less likely to guess the aim of the study.
The same materials can be used across groups. For example, a memory test could give both groups the same word list.
DISADVANTAGES
Individual differences – Participants in each condition may differ in ways that affect the results (e.g., personality, IQ, age).
Larger sample needed—Repeated measures require twice as many participants to gather the same amount of data.
The researcher may be biased in assigning participants to conditions. Therefore, he/she should randomly allocate participants using random number tables, such as computer-generated random number tables. These are the same as the advantages and disadvantages of repeated measures, but in reverse.

BETWEEN-GROUP QUASI DESIGN
QUASI-EXPERIMENTAL DESIGN (BETWEEN-SUBJECTS QUASI)
Once a researcher has chosen to experiment, they must decide how to organise participants into different conditions. In some cases, however, random allocation is not possible or appropriate. This is where a quasi-experimental design is used.
In a between-subjects quasi-experiment, participants are deliberately assigned to naturally existing groups that differ on a key variable—for example, male vs. female, smoker vs. non-smoker, or ASD diagnosis vs. no diagnosis. These pre-existing groups become the independent variable. The researcher then compares how these groups perform on a dependent variable.
Although this is not the same as an independent groups design, because there is no random allocation, it functions similarly when it comes to statistical testing. To choose an inferential test, you treat it the same as an independent groups design.
This is the type of quasi-experiment AQA tends to assess.
KEY CHARACTERISTICS
There is no random allocation — groups are already formed.
The researcher uses these naturally occurring groups as conditions.
The researcher does not manipulate the IV, but compares existing groups.
Still carried out under experimental conditions — often in a lab.
Used to investigate differences between groups on a DV.

WHY USE A BETWEEN-SUBJECTS QUASI?
The researcher exploits existing differences as a basis for comparison.
The groups themselves are the IV, so although not truly experimental, this design allows for group comparisons.
EXAMPLES
Comparing males vs females on aggression after playing a video game.
Investigating whether ASD students score differently on a memory task than neurotypical students.
Looking at whether smokers perform worse on concentration tasks than non-smokers

REPEATED MEASURES DESIGN DEFINITION
A Repeated Measures design is an experimental design in which the same participants participate in each condition of the independent variable. This means that each condition of the experiment includes the same group of participants. Repeated Measures design is also known as a within-groups or within-subjects design.

ADVANTAGES
The two groups have the same age, sex, personality, ideas, past experiences, IQ, reaction times (crucially for this one), etc. They are perfectly matched—they are the same people!
Fewer people are needed.
DISADVANTAGES
Order effects: Assuming that we expect the group to do better on the second day, can we be sure that this increase in performance is due to the coffee? They could have had the chance to practice the task the day before! It’s not surprising they’re better the second time around. This is called the order or practice effect.
Boredom: Of course, on some tasks, it could work the other way, and a task done the second time shows deterioration because they’re fed up with doing it.
Extra materials: For example, if you use the same participants for two memory experiments, you will need two lists of words, etc., for them to recall. This introduces other variables. Perhaps the second list is easier than the first.
Demand characteristics. They have already done one condition; they will probably guess what the experiment is about.
EXAMPLE: REPEATED MEASURES DESIGN APPLIED TO RESEARCH
INTRODUCTION
A SUMMARY OF AVAILABLE RESEARCH: Many people have heard of the “Mozart Effect” or a similar idea. This hypothesis questions whether a person who listens to Mozart's compositions before a test scores higher than one who does not. It’s theorised that music increases beta-waves, beta-waves increase attention, and attention increases intelligence. In addition, hearing is lateralised; there are different sound specialisations on each half of the brain. The left hemisphere has an advantage for decoding speech, and the right hemisphere for decoding music and other non-human noise.
JUSTIFICATION: The researcher hypothesises that because speech and music are processed independently in the brain, music should not affect performance (as long as it does not have lyrics). Moreover, cognitive tasks should be more manageable because music increases beta waves.
AIMS: A researcher develops a theory based on this finding and wonders if listening to music will affect tasks that require thinking or analysing, e.g., listening to the radio whilst writing an essay or solving a maths problem. Because there was previous research, a directional (1-tailed) hypothesis was chosen.
The researcher created the following null and alternative/experimental hypotheses:
NULL HYPOTHESIS: There will be no difference between participants in the “music condition” and participants in the “no music” condition, and their scores on an IQ test.
ALTERNATIVE HYPOTHESIS: Participants in the “music condition” will score higher on an IQ test than participants in the “no music condition”
METHOD
DESIGN: A laboratory experiment with a Repeated Measures Design. The independent variable is music operationalised as Mozart's Sonata No. 11; the control condition is no music. The dependent variable is the scores on the Stanford-Binet IQ test.
The conditions are either:
Taking an IQ test whilst listening to music
Taking an IQ test whilst listening to no music
PROCEDURES: The researcher conducts a pilot study with ten volunteer participants from a local SEN school.
RESULTS
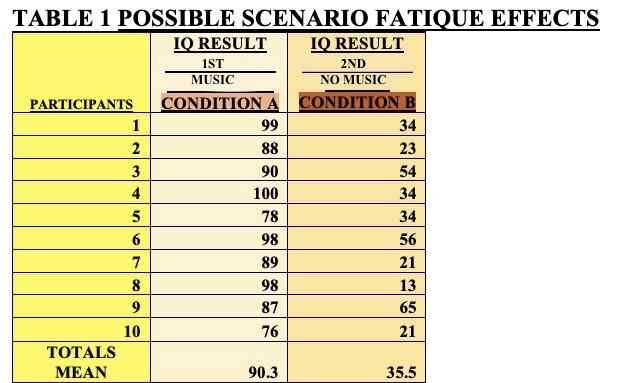
DESCRIPTIVE STATISTICS BELOW IN TABLE 1
REPEATED MEASURES DESIGN AND ORDER EFFECTS
In a repeated measures design, all participants participate in both experiment conditions. That’s what makes it worthwhile — you control for individual differences. But there’s a catch: order effects.
Order effects happen because participants do both conditions, and their order matters. So, should you have participants complete the music condition first or the no music condition first?
It doesn’t matter. Both options can be flawed.
TABLE 1: FATIGUE OR BOREDOM EFFECTS
In the example shown in Table 1, all participants take Condition A (music) first. Look at the results — scores are much higher in Condition A than in Condition B. You might assume the music condition improves IQ scores. But not so fast — this could be due to boredom or fatigue in the second condition. When participants take the first test, they’re usually more focused — they want to do well. But by the second test, they’ve lost interest, got bored, or mentally switched off. That means performance drops, not because of the IV, but because of the order.
The researcher might wrongly conclude that the IV (music) made a difference when, really, it was just participants who were tired or demotivated by the second round.
EXPERT OR PRACTICE EFFECTS (TABLE 2)
There’s another issue — the opposite of boredom. Instead of losing motivation, some participants get better at the task after doing it once. They’ve figured out how the test works and improved simply because it’s now familiar. These are called practice or expert effects.
The second condition might score higher in this case, not because the IV helped, but because participants knew what to expect. Again, the results get distorted.

SO WHAT’S THE SOLUTION?
The answer is counterbalancing.
Instead of all participants doing the conditions in the same order, researchers split the group in half.
Group one does Condition A first, then Condition B.
Group two does Condition B first, then Condition A.
This way, any order effects are spread evenly across both conditions.
If participants get bored by the second task, that boredom will affect both conditions equally — some during music, some without. Likewise, if they improve through practice, that improvement also gets balanced across the groups.
By counterbalancing, researchers can be more confident that any differences in results are due to the IV, not just the order of testing.




