

SAMPLING

SPECIFICATION: Sampling: the difference between population and sample; sampling techniques including random, systematic, stratified, opportunity and volunteer; implications of sampling techniques, including bias and generalisation
Data plays an essential role in research. It is crucial to make sure that the data collected is suitable for the problem at hand. The data being used must be relevant, correct, and representative of all classes, races, religions and subcultures etc One of the most important issues about any type of sampling method is how representative of the population the results are.
WHAT IS A POPULATION?
The population refers to the entire group of individuals about whom you wish to draw conclusions.
An example of a population would be: “All the students in a university.” The population would contain all the students who studied at that university at the time of data collection. Any kind of data can be collected from small populations such as this. For example, students who who suffer from depression. For the above situation, it is easy to collect data because the population is small, willing to provide data and can students can be contacted. The data collected will be complete and reliable.
If you had to collect the same data from a larger population, say all the universities in the UK , it would be impossible to draw reliable conclusions because of geographical accessibility and constraints, not to mention time and resource constraints. A lot of data would be missing or might be unreliable. Furthermore, due to accessibility issues or circumstances, some students might not provide information at all, perhaps making the data biased towards certain regions or groups.
WHAT IS A SAMPLE?

The sample refers to the group of people from which you will be collecting data.
The population is the group of people from whom the sample is drawn. For example if the sample of participants is taken from sixth form colleges in Erith, the findings of the study can only be applied to that group of people and not all sixth form students in the UK and certainly not all people in the world. Obviously it is not usually possible to test everyone in the target population so therefore psychologists use sampling techniques to choose people who are representative (typical) of the population as a whole.
A sample is defined as a smaller and more manageable representation of a larger group. A subset of a larger population that contains characteristics of that population. A sample is used in statistical testing when the population size is too large for all members or observations to be included in the test. The sample should be an unbiased subset of the population that best represents the whole data. The results obtained for different groups who took part in the study can be extrapolated to generalise for the population.
Say you are looking for a romantic date with similar aged person. First, you search online for singletons in their late teens . The first search result would be for people around the world. But you want to date people in your area, so you search for single teens in Kent. This would be your population. It would be impossible to go through the dating websites and profiles in this area. So you consider the top two dating websites that cover Kent and start looking through those. This is your sample.
DIFFERENT SAMPLING METHODS
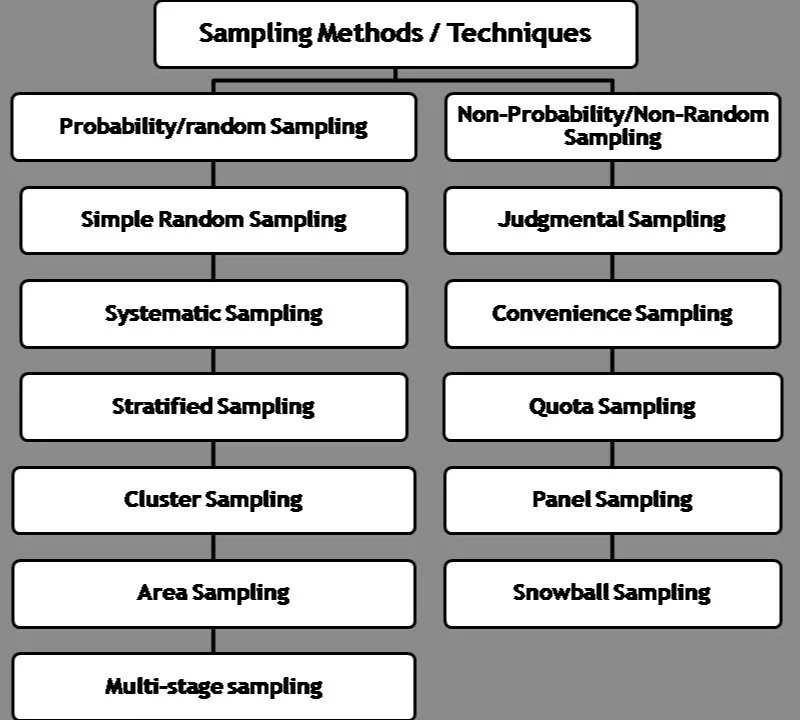
NON PROBABILITY SAMPLING METHODS
Opportunity Sampling
Opportunity sampling is the sampling technique most used by psychology students. It consists of taking the sample from people who are available at the time the study is carried out and fit the criteria you are looking for. This may simple consist of choosing the first 20 students in your college canteen to fill in your questionnaire. It is a popular sampling technique as it is easy in terms of time and therefore money. For example the researcher may use friends, family or colleagues. It can also be seen as adequate when investigating processes which are thought to work in similar ways for most individuals such as memory processes. Sometimes, particularly with natural experiments opportunity sampling has to be used as the researcher has no control over who is studied. However, there are many weaknesses of opportunity sampling. Opportunity sampling can produce a biased sample as it is easy for the researcher to choose people from their own social and cultural group. This sample would therefore not be representative of your target population as you friends may have different qualities to people in general.

A further problem with opportunity sampling is that participants may decline to take part and your sampling technique may turn into a self-selected sample. This involves identifying everyone in the target population and then selecting the number of participants you need in a way that gives everyone in the population an equal chance of being picked. For example, you could put all of the names of the students at your college in a hat and pick out however many you need.
SNOWBALL SAMPLING
Snowball sampling can be used if your population is not easy to contact. For example if you were interested in studying students who take illegal drugs you may ask a participant who fits your target population to tell their friends about the study and ask them to get in touch with the researcher and so on.
VOLUNTEER SAMPLING

Volunteer sampling (or self-selected sampling) consists of participants becoming part of a study because they volunteer when asked or in response to an advert. This sampling technique is used in a number of the core studies, for example Milgram (1963). This technique, like opportunity sampling, is useful as it is quick and relatively easy to do. It can also reach a wide variety of participants. However, the type of participants who volunteer may not be representative of the target population for a number of reasons. For example, they be more obedient, more motivated to take part in studies and so on.
QUOTA SAMPLE
If the sample is not randomly selected from the categories it is then called a quota sample.

PROBABILITY SAMPLING (RANDOM SAMPLES)
Probability sampling is a sampling method that involves randomly selecting a sample, or a part of the population that you want to research. It is also sometimes called random sampling. To qualify as being random, each research unit (e.g., person, business, or organisation in your population) must have an equal chance of being selected. This is usually done through a random selection process, like a drawing, to minimise the risk of selection bias.
Types of probability sampling
There are four commonly used types of probability sampling designs:
Simple random sampling
Stratified sampling
Systematic sampling
Cluster sampling

.
SIMPLE RANDOM SAMPLE
The term random has a very precise meaning. Each individual in the population of interest has an equal likelihood of selection. This is a very strict meaning -- you can't just collect responses on the street and have a random sample. This involves identifying everyone in the target population and then selecting the number of participants you need in a way that gives everyone in the population an equal chance of being picked. For example, you could put all of the names of the students at your college in a hat and pick out however many you need.
The assumption of an equal chance of selection means that sources such as a telephone book or voter registration lists are not adequate for providing a random sample of a community. In both these cases there will be a number of residents whose names are not listed. Telephone surveys get around this problem by random-digit dialling -- but that assumes that everyone in the population has a telephone. The key to random selection is that there is no bias involved in the selection of the sample. Any variation between the sample characteristics and the population characteristics is only a matter of chance.
Random sampling is the best technique for providing an unbiased representative sample of a target population. However random sampling does have limitations. Random sampling can be very time consuming and is often impossible to carry out, particularly when you have a large target population, of say all students in the UK. For example if you do not have the names of all the people in your target population you would struggle to conduct a random sample. If you ask people to volunteer for a study the sample is already not random as some people may be more or less likely to volunteer for things. Similarly if you decided to put out an advert for participants it would be almost impossible to guarantee that every member of your target population has an equal chance of viewing the advert.
To compile a list of the units in your research population, consider using a random number generator. There are several free ones available online, such as random.org, calculator.net, and randomnumbergenerator.org.
Example: Simple random sampling
You are researching the political views of a municipality of 4,000 inhabitants. You have access to a list with all 4,000 people,anonymisedfor privacy reasons. You have established that you need a sample of 100 people for your research.
Writing down the names of all 4,000 inhabitants by hand to randomly draw 100 of them would be impractical and time-consuming, as well as questionable for ethical reasons. Instead, you decide to use a random number generator to draw a simple random sample.
If the first number generated by the program is 1735, this means that resident #1735 on your list should be selected to be part of the sample. You continue by matching each number with the respective resident on the list.
STRATIFIED SAMPLE

The best sampling is stratified sampling because it increases the likelihood of obtaining samples that are representative of the population. Stratified samples are selected in such a way as to be representative of the population. They provide the most valid or credible results because they reflect the characteristics of the population from which they are selected (e.g., residents of a particular community, students at an elementary school, etc.).
A stratified sample is a mini-reproduction of the population. Before sampling, the population is divided into characteristics of importance for the research. For example, by gender, social class, education level, religion, etc. Then the population is randomly sampled within each category or stratum. In other words, Stratified sampling involves classifying the population into categories and then choosing a sample which consists of participants from each category in the same proportions as they are in the population. For example, if you wanted to carry out a stratified sample of students from a sixth form college you might decide that important variables are sex, age, have a part-time job and so on. You could then identify how many participants there are in each of these categories and choose the same proportion of participants in these categories for your study If 38% of the population is college-educated, and then 38% of the sample is randomly selected from the college-educated population.
Stratified samples are better than random samples, but they require fairly detailed advance knowledge of the population characteristics, but are more difficult to construct.
Another strength of stratified sampling is therefore that your sample should be representative of the population. However, stratified sampling can be very time consuming as the categories have to be identified and calculated. As with random sampling, if you do not have details of all the people in your target population you would struggle to conduct a stratified sample. Stratified sampling collects a random selection of a sample from within certain strata, or subgroups within the population. Each subgroup is separated from the others on the basis of a common characteristic, such as gender, race, or religion. This way, you can ensure that all subgroups of a given population are adequately represented within your sample population.
For example, if you are dividing a student population by college majors, Engineering, Linguistics, and Physical Education students are three different strata within that population.
To split your population into different subgroups, first choose which characteristic you would like to divide them by. Then you can select your sample from each subgroup. You can do this in one of two ways:
By selecting an equal number of units from each subgroup
By selecting units from each subgroup equal to their proportion in the total population
Example: Stratified sampling
You are investigating why young people choose to play basketball. You want to know if children from urban areas are more likely to play than children from rural areas. As you look at a list of all the youth players in your state, you notice that there are 32,000 children from urban areas and 8,000 children from rural areas.
If you take a simple random sample, children from urban areas will have a far greater chance of being selected, so the best way of getting a representative sample is to take a stratified sample.
First, you divide the population into your strata: one for children from urban areas and one for children from rural areas. Then, you take a simple random sample from each subgroup. You can use one of two options:
Select 100 urban and 100 rural, i.e., an equal number of units
Select 80 urban and 20 rural, which gives you a representative sample of 100 people
Then, you can continue with your data collection (e.g., ask them to fill in a questionnaire). If you choose an equal number of units, keep in mind that you need to weigh the results in order to draw conclusions for the population as a whole. In this case, since children from urban areas form 80% of the population, you will have to weigh their results eight times more than those of the children from rural areas.
SYSTEMATIC SAMPLING

Systematic sampling draws a random sample from the target population by selecting units at regular intervals starting from a random point. This method is useful in situations where records of your target population already exist, such as records of an agency’s clients, enrollment lists of university students, or a company’s employment records. Any of these can be used as a sampling frame.
To start your systematic sample, you first need to divide your sampling frame into a number of segments, called intervals. You calculate these by dividing your population size by the desired sample size.
Then, from the first interval, you select one unit using simple random sampling. The selection of the next units from other intervals depends upon the position of the unit selected in the first interval.
Note
The selection of a unit within the first interval is random, but the selection of units from the next intervals depends on the first selection you made. For this reason, systematic sampling design is sometimes viewed as a mixed design.
Let’s refer back to our example about the political views of the municipality of 4,000 inhabitants. You can also draw a sample of 100 people using systematic sampling. To do so, follow these steps:
Determine your interval: 4,000 / 100 = 40. This means that you must select 1 inhabitant from every 40 in the record.
Using simple random sampling (e.g. a random number generator), you select 1 inhabitant.
Let’s say you select the 11th person on the list. In every subsequent interval, you need to select the 11th person in that interval, until you have a sample of 100 people.
Note
For this to work, you must be completely sure that there is no hidden pattern or hierarchical order in the sampling frame, as this can bias your results.
For example, suppose you have a list of all the employees in an organisation divided by department. If each department list is also organised by seniority (starting with the most senior person and ending with the most recent hire), you run the risk of only selecting the more senior or junior employees, depending on what number you set as your interval.
CLUSTER SAMPLING

Cluster sampling is the process of dividing the target population into groups, called clusters. A randomly selected subsection of these groups then forms your sample. Cluster sampling is an efficient approach when you want to study large, geographically dispersed populations. It usually involves existing groups that are similar to each other in some way (e.g., classes in a school).
There are two types of cluster sampling:
Single (or one-stage) cluster sampling, when you divide the entire population into clusters
Multistage cluster sampling, when you divide the cluster further into more clusters, in order to narrow down the sample size
Example: Single-stage cluster sampling
You are researching the perceptions of sixth-form students about higher education. It is not feasible to get a list of all sixth-form students in your region, but you are able to access your city’s data following required privacy protocols.
Clusters are pre-existing groups, so each sixth-form college is a cluster, and you assign a number to each one of them. Then, you use simple random sampling to further select clusters. How many clusters you select will depend on the sample size that you need.
Next, you contact the headteacher of each selected college and ask them to collaborate with you by disseminating your questionnaire to their students.
Multi-stage sampling is a more complex form of cluster sampling, in which smaller groups are successively selected from larger populations to form the sample population used in your study.
Example: Multi-stage sampling
You are investigating workplace-related stress in an ed-tech company. You want to draw a sample of employees to survey. In the organisational chart, you see that the company consists of 9 departments, and each department consists of 2 to 4 units, resulting in 17 different units in total.
First, you take a simple random sample of departments. Then, again using simple random sampling, you select a number of units. Based on the size of the population (i.e., how many employees work at the company) and your desired sample size, you establish that you need to include 3 units in your sample.
Once you have made your selection, you ask every employee working in the selected units to fill in your questionnaire.
In stratified sampling, you divide your population in groups (strata) that share a common characteristic and then select some members from every group for your sample. In cluster sampling, you use pre-existing groups to divide your population into clusters and then include all members from randomly selected clusters for your sample.

Examples of probability sampling methods
There are a few methods you can use to draw a random sample. Here are a few examples:
The fishbowl draw
A random number generator
The random number function
Fishbowl draw
You are investigating the use of a popular portable e‐reader device among library and information science students and its effects on individual reading practices. You write the names of 25 students on pieces of paper, put them in a jar, and then, without looking, randomly select three students to be interviewed for your research.
All students have equal chances of being selected and no other consideration (such as personal preference) can influence this selection. This method is suitable when your total population is small, so writing the names or numbers of each unit on a piece of paper is feasible.
Random number generator
Suppose you are researching what people think about road safety in a specific residential area. You make a list of all the suburbs and assign a number to each one of them. Then, using an online random number generator, you select four numbers, corresponding to four suburbs, and focus on them.
This works best when you already have a list with the total population and you can easily assign every individual a number.
RAND function in Microsoft Excel
If your data are in a spreadsheet, you can also use the random number function (RAND) in Microsoft Excel to select a random sample.
Suppose you have a list of 4,000 people and you need a sample of 300. By typing in the formula =RAND() and then pressing enter, you can have Excel assign a random number to each name on the list. For this to work, make sure there are no blank rows.
Differences Between Population and Sample
Now, try to understand what a sample and a population are, with the help of suitable examples.
Population
All residents of a country would constitute the Population set
All residents above the poverty line in a country would be the PopulationSample
All employees in an office would be the Population
Sample
All residents who live above the poverty line would be the Sample
All residents who are millionaires would make up the Sample
Out of all the employees, all managers in the office would be the Sample

Possible Exam Questions
Identify, from the descriptions below, which scenario represents a systematic sampling method. (1 mark)
a) A psychologist places an advert in a local newspaper, asking for participants.
b) A psychologist uses lists of undergraduates from the nearby university and selects every fifthstudent to take part.
c) A psychologist asks some of her mathematics students to take part in the research.
d) A psychologist gives a number to all students in the psychology class then selects participants in anunbiased way.
A criminal psychologist adopted an independent groups design to research the effectiveness of the cognitive interview compared to the standard police interview. For this research study, participants were gathered by placing an advert on Facebook. The advert told the prospective participants that, as part of the procedure, they would be required to watch a short film of a violent crime. Afterwards, they would then be interviewed about what they saw by a female police officer.
After twenty participants completed the study, ten in each condition, the criminal psychologist compared the average number of items recalled in the cognitive interview with the average number of items correctly recalled in the standard police interview.
Name the sampling technique used in this experiment. (1 mark)
Exam Hint: Most students will be able identify volunteer / self‐selected sampling since the Facebook advert was used to encourage users of the social media site to apply for participation in the investigation.
Explain one strength of random sampling. (2 marks)
Suggest one limitation of volunteer sampling in psychological research. (2 marks)
Exam Hint: One mark is available here for identifying a suitable limitation and the second mark is achieved by elaborating on this successfully. For example: One limitation of using a volunteer sample in psychological research is that it can be biased. This is often the case because some people, with certain characteristics, are more likely to volunteer than others. Consequently, these characteristics will be overrepresented, making the sample biased.
5. Explain how stratified sampling might be used to select participants. (3 marks)
Exam Hint: Note that this question is asking how stratified sampling is conducted, and does not require any strengths or limitations to be offered. To achieve full credit, students must logically explain the process a psychologist would undergo in achieving a stratified sample so they can generalise the results to the target population.
Explain at least one difference between random and opportunity sampling. (4 marks)
Evaluate the use of opportunity sampling as a technique for gathering participants to take part in an investigation. (4 marks)
8. Outline and evaluate one or more sampling technique used in psychological research. (8 marks)
Exam Hint: Whilst this is an eight‐mark question, it is worth unpicking the structure to consider the different elements required. For example, this question could be interpreted as: 1) Outline and evaluate sampling method 1 (e.g. random); and 2) Outline and evaluate sampling method 2 (e.g. opportunity). This would then allow a student to consider this as two four‐mark questions, rather than one larger one.